XGBoost#
XGBoost (eXtreme Gradient Boosting) is a machine learning library which implements supervised machine learning models under the Gradient Boosting framework.
In this tutorial we’ll cover how to perform XGBoost regression in Python. We will focus on the following topics:
How to define hyperparameters
Model fitting and evaluating
Obtain feature importance
Perform cross-validation
Hyperparameter tuning
Install xgboost:
conda install -c conda-forge py-xgboost
Setup#
%matplotlib inline
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)
import numpy as np
import pandas as pd
from pandas import MultiIndex, Int64Index
import matplotlib.pyplot as plt
import xgboost as xgb
print("XGB Version:", xgb.__version__)
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.inspection import permutation_importance
from sklearn.model_selection import GridSearchCV
XGB Version: 1.7.1
Data#
We use data drawn from the 1990 U.S. Census to predict median house value for households within a block (see this data description for more information).
Data import#
X, y = datasets.fetch_california_housing(return_X_y=True, as_frame=True)
feature_names = X.columns
X.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 20640 entries, 0 to 20639
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 MedInc 20640 non-null float64
1 HouseAge 20640 non-null float64
2 AveRooms 20640 non-null float64
3 AveBedrms 20640 non-null float64
4 Population 20640 non-null float64
5 AveOccup 20640 non-null float64
6 Latitude 20640 non-null float64
7 Longitude 20640 non-null float64
dtypes: float64(8)
memory usage: 1.3 MB
Data splitting#
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=0)
Model building#
Hyperparameters#
XGBoost provides many hyperparameters but we will only consider a few of them (see the XGBoost documentation for an complete overview).
Note that we will use the scikit-learn wrapper interface:
objective: determines the loss function to be used likereg:squarederrorfor regression problems,binary:logisticfor logistic regression for binary classification ormulti:softmaxto do multiclass classification using the softmax objectiv (note that there are more options).n_estimators: Number of gradient boosted trees. Equivalent to number of boosting rounds.max_depth: Maximum tree depth for base learners.learning_rate: Boosting learning rate (xgb’s “eta”). Range is [0,1].subsample: Subsample ratio of the training instance. Setting it to 0.5 means that XGBoost would randomly sample half of the training data prior to growing trees.colsample_bytree: Subsample ratio of columns when constructing each tree. Subsampling occurs once for every tree constructed.colsample_bylevel: Subsample ratio of columns for each level. Subsampling occurs once for every new depth level reached in a tree. Columns are subsampled from the set of columns chosen for the current tree.gamma: Minimum loss reduction required to make a further partition on a leaf node of the tree. A higher value leads to fewer splits.reg_alpha: L1 regularization term on weights (xgb’s alpha). A large value leads to more regularization.reg_lambda: L2 regularization term on weights (xgb’s lambda).eval_metric(default is according to objective). Evaluation metrics for validation data, a default metric will be assigned according to objective (rmsefor regression, andloglossfor classificationestimator ).random_state: Random number seed.early_stopping_rounds: If you have a validation set, you can use early stopping to find the optimal number of boosting rounds. Early stopping requires at least one set in evals. If there’s more than one, it will use the last. Note that we include this parameter in our fit function.
Define hyperparameters as dictionary:
params = {
"objective": "reg:squarederror",
"n_estimators":100,
"max_depth": 4,
"learning_rate": 0.01,
"subsample": 0.8,
"colsample_bytree": 0.9,
"colsample_bylevel": 0.8,
"reg_lambda": 0.1,
"eval_metric": "rmse",
"random_state": 42,
}
Fit model#
reg = xgb.XGBRegressor(**params)
Since we want to plot the learning curves for both training and test data, we need to provide both training and test data as eval_set. Furthermore, if you provide a validation set, you can use “early stopping” to find the optimal number of boosting rounds (early stopping requires at least one set in evals. If there’s more than one, it will use the last).
Note
Early stoping: The model will train until the validation score stops improving. Validation error needs to decrease at least every early_stopping_rounds to continue training.
If early stopping occurs, the model will have two additional fields:
reg.best_score,reg.best_iteration
Note
Xgboost will always return a model from the last iteration, not the best one.
reg.fit(X_train,
y_train,
verbose=False,
eval_set= [(X_train, y_train), (X_test, y_test)],
early_stopping_rounds= 3
)
XGBRegressor(base_score=0.5, booster='gbtree', callbacks=None,
colsample_bylevel=0.8, colsample_bynode=1, colsample_bytree=0.9,
early_stopping_rounds=None, enable_categorical=False,
eval_metric='rmse', feature_types=None, gamma=0, gpu_id=-1,
grow_policy='depthwise', importance_type=None,
interaction_constraints='', learning_rate=0.01, max_bin=256,
max_cat_threshold=64, max_cat_to_onehot=4, max_delta_step=0,
max_depth=4, max_leaves=0, min_child_weight=1, missing=nan,
monotone_constraints='()', n_estimators=100, n_jobs=0,
num_parallel_tree=1, predictor='auto', random_state=42, ...)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
XGBRegressor(base_score=0.5, booster='gbtree', callbacks=None,
colsample_bylevel=0.8, colsample_bynode=1, colsample_bytree=0.9,
early_stopping_rounds=None, enable_categorical=False,
eval_metric='rmse', feature_types=None, gamma=0, gpu_id=-1,
grow_policy='depthwise', importance_type=None,
interaction_constraints='', learning_rate=0.01, max_bin=256,
max_cat_threshold=64, max_cat_to_onehot=4, max_delta_step=0,
max_depth=4, max_leaves=0, min_child_weight=1, missing=nan,
monotone_constraints='()', n_estimators=100, n_jobs=0,
num_parallel_tree=1, predictor='auto', random_state=42, ...)Save model#
Save the model into JSON format (optional)
#reg.save_model("regressor.json")
Evaluation#
Obtain all evaluation results:
results = reg.evals_result()
Coefficient of determination#
Return the coefficient of determination (\(R^2\)) of the prediction:
# for training data
reg.score(X_train, y_train, sample_weight=None)
0.30197816458883875
# for test data
reg.score(X_test, y_test, sample_weight=None)
0.30315081477332295
RMSE#
XGBoost functions#
Show evaluation result (
rmse) for our test data (validation_1) for the last model in the list (-1)
results['validation_1']['rmse'][-1]
0.9786155477636489
Next, we obtain our best iteration (this attribute is 0-based, for instance if the best iteration is the 100th round, then best_iteration is 99).
best_iter = reg.best_iteration
best_iter
99
Show result for best iteration (in our case, the last iteration and best iteration are identical)
results['validation_1']['rmse'][best_iter]
0.9786155477636489
Scikit-learn functions#
Next, we use the scikit-learn workflow to obtain our evaluation metrics.
Make predictions
y_pred = reg.predict(X_test)
Obtain RMSE with skicit-learn function
mean_squared_error:
mean_squared_error(y_test, y_pred, squared = False)
0.9786155477422379
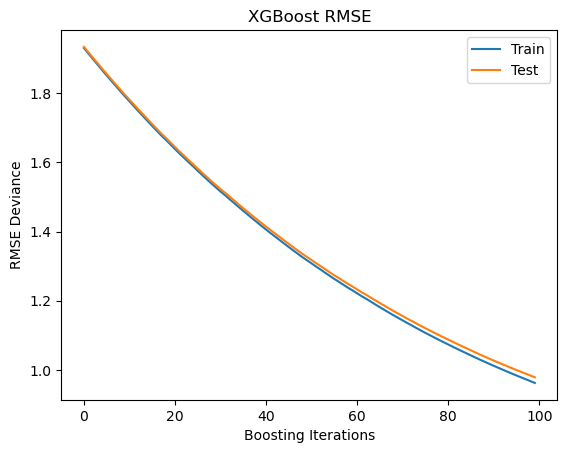
Train test deviance#
Plot training test deviance
# Prepare x-axis
epochs = len(results['validation_0']['rmse'])
x_axis = range(0, epochs)
fig, ax = plt.subplots()
ax.plot(x_axis, results['validation_0']['rmse'], label='Train')
ax.plot(x_axis, results['validation_1']['rmse'], label='Test')
plt.title('XGBoost RMSE')
plt.xlabel("Boosting Iterations")
plt.ylabel("RMSE Deviance")
plt.legend(loc="upper right");
Visualize tree#
You need to install graphviz to plot the tree. For Anaconda, use
conda install -c conda-forge python-graphviz
plt.rcParams['figure.figsize'] = [50, 10]
xgb.plot_tree(reg ,num_trees=0);

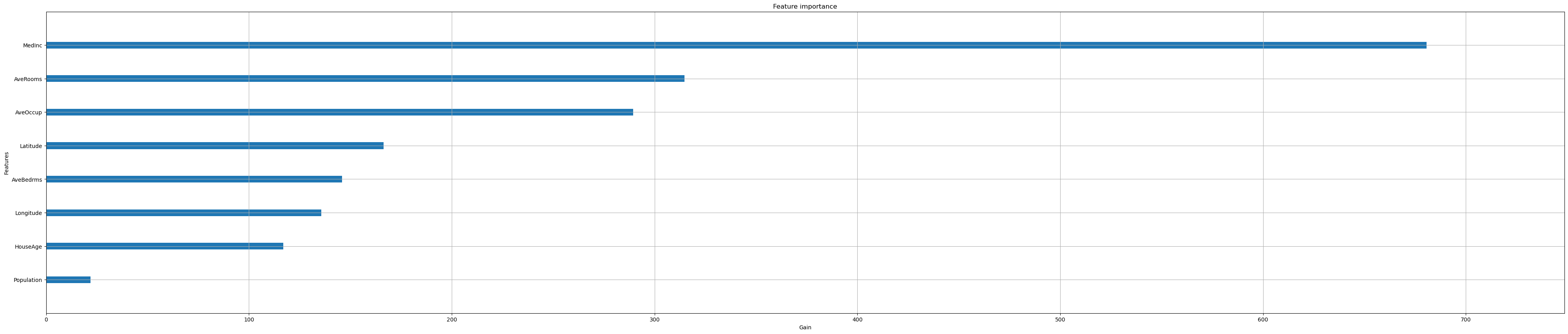
Feature importance#
Next, we take a look at the tree based feature importance and the permutation feature importance.
Feature importance#
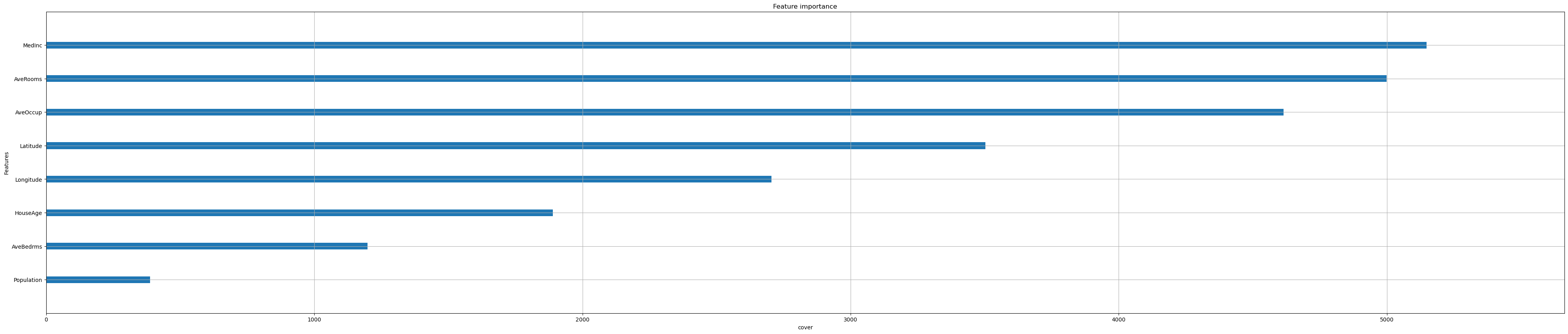
Importance is calculated with either “weight”, “gain”, or “cover”
”weight” is the number of times a feature appears in a tree
”gain” is the average gain of splits which use the feature
”cover” is the average coverage of splits which use the feature (where coverage is defined as the number of samples affected by the split)
reg.feature_importances_
array([0.3636188 , 0.0625032 , 0.1681831 , 0.07790712, 0.01166479,
0.15469898, 0.08890024, 0.07252375], dtype=float32)
Feature importances are provided by the function
plot_importance
xgb.plot_importance(reg,
importance_type="gain",
show_values=False,
xlabel="Gain");
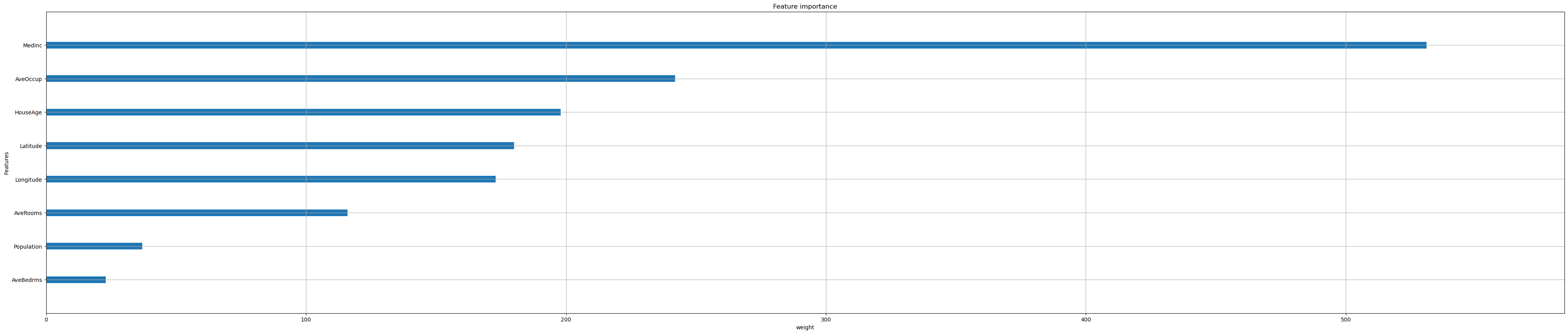
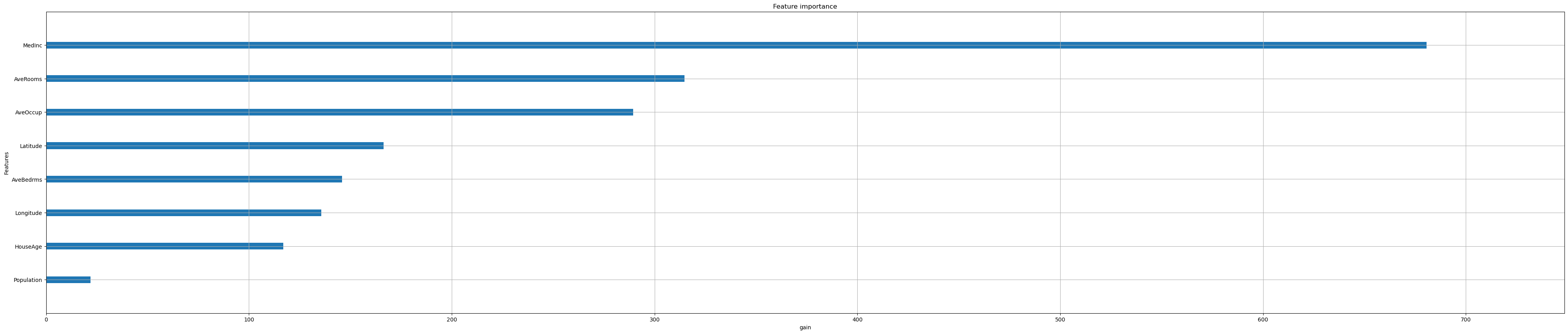
Iterate over all options:
feat_importance = ["weight", "gain", "cover"]
for i in feat_importance:
xgb.plot_importance(reg,
importance_type=i,
show_values=False,
xlabel=i);
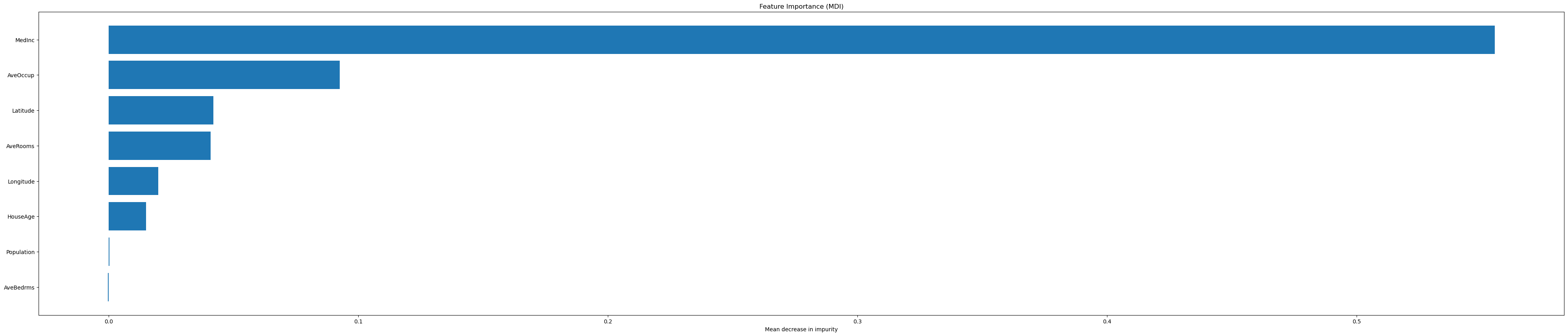
Permutation feature importance#
The permutation feature importance is defined to be the decrease in a model score when a single feature value is randomly shuffled.
Note
Visit this notebook to learn more about permutation feature importance.
We will use the scikit-learn function
permutation_importance:
result = permutation_importance(
reg, X_test, y_test, n_repeats=10, random_state=42
)
# make a pandas data series
tree_importances = pd.Series(result.importances_mean, index=feature_names)
# sort features according to importance
sorted_idx = np.argsort(tree_importances)
pos = np.arange(sorted_idx.shape[0])
# plot feature importances
plt.barh(pos, tree_importances[sorted_idx], align="center")
plt.yticks(pos, np.array(feature_names)[sorted_idx])
plt.title("Feature Importance (MDI)")
plt.xlabel("Mean decrease in impurity");
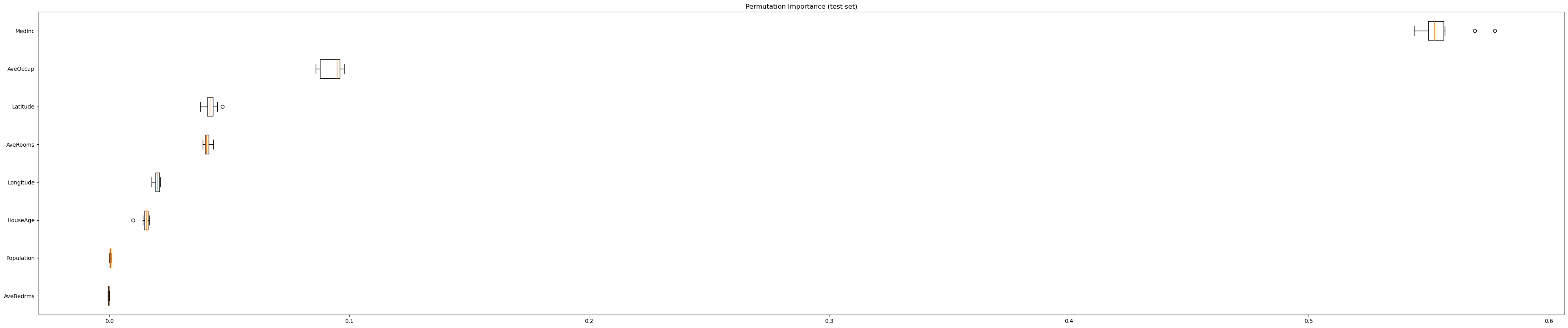
Same data plotted as boxplot:
plt.boxplot(
result.importances[sorted_idx].T,
vert=False,
labels=np.array(feature_names)[sorted_idx],
)
plt.title("Permutation Importance (test set)")
plt.show()
Cross-validation#
Next, we use k-fold cross validation to build even more robust trees.
First, we will convert the dataset into an optimized data structure called Dmatrix.
dmatrix = xgb.DMatrix(data=X,label=y)
We use the same hyperparameteras as before.
We just drop
num_estimatorsand instead usenum_boost_roundin our fit.
params_cv = {
"objective": "reg:squarederror",
"max_depth": 4,
"learning_rate": 0.01,
"subsample": 0.8,
"colsample_bytree": 0.9,
"colsample_bylevel": 0.8,
"reg_lambda": 0.1,
"eval_metric": "rmse",
"random_state": 42,
}
Perform 3-fold-cross-validation:
reg_cv = xgb.cv(dtrain=dmatrix,
nfold=3,
params=params_cv,
num_boost_round=5,
early_stopping_rounds=10,
metrics="rmse",
as_pandas=True,
seed=123)
reg_cv.head()
| train-rmse-mean | train-rmse-std | test-rmse-mean | test-rmse-std | |
|---|---|---|---|---|
| 0 | 1.930837 | 0.008074 | 1.930872 | 0.016105 |
| 1 | 1.914908 | 0.008166 | 1.914989 | 0.015754 |
| 2 | 1.898777 | 0.008120 | 1.898905 | 0.015531 |
| 3 | 1.882704 | 0.008067 | 1.882887 | 0.015338 |
| 4 | 1.866843 | 0.007958 | 1.867077 | 0.015233 |
Extract and print the final boosting round metric.
print((reg_cv["test-rmse-mean"]).tail(1))
4 1.867077
Name: test-rmse-mean, dtype: float64
Hyperparameter Tuning#
Let’s demonstrate hyperparameter tuning for some parameters:
params = { 'max_depth': [3,6],
'learning_rate': [0.01, 0.05],
'n_estimators': [3, 5],
'colsample_bytree': [0.3, 0.7]}
reg_h = xgb.XGBRegressor(seed = 42)
reg_hyper = GridSearchCV(estimator=reg_h,
param_grid=params,
scoring='neg_mean_squared_error',
verbose=1)
This will take a while …
reg_hyper.fit(X_train, y_train)
Fitting 5 folds for each of 16 candidates, totalling 80 fits
GridSearchCV(estimator=XGBRegressor(base_score=None, booster=None,
callbacks=None, colsample_bylevel=None,
colsample_bynode=None,
colsample_bytree=None,
early_stopping_rounds=None,
enable_categorical=False, eval_metric=None,
feature_types=None, gamma=None, gpu_id=None,
grow_policy=None, importance_type=None,
interaction_constraints=None,
learning_rate=None, max_bi...
max_cat_to_onehot=None, max_delta_step=None,
max_depth=None, max_leaves=None,
min_child_weight=None, missing=nan,
monotone_constraints=None, n_estimators=100,
n_jobs=None, num_parallel_tree=None,
predictor=None, random_state=None, ...),
param_grid={'colsample_bytree': [0.3, 0.7],
'learning_rate': [0.01, 0.05], 'max_depth': [3, 6],
'n_estimators': [3, 5]},
scoring='neg_mean_squared_error', verbose=1)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
GridSearchCV(estimator=XGBRegressor(base_score=None, booster=None,
callbacks=None, colsample_bylevel=None,
colsample_bynode=None,
colsample_bytree=None,
early_stopping_rounds=None,
enable_categorical=False, eval_metric=None,
feature_types=None, gamma=None, gpu_id=None,
grow_policy=None, importance_type=None,
interaction_constraints=None,
learning_rate=None, max_bi...
max_cat_to_onehot=None, max_delta_step=None,
max_depth=None, max_leaves=None,
min_child_weight=None, missing=nan,
monotone_constraints=None, n_estimators=100,
n_jobs=None, num_parallel_tree=None,
predictor=None, random_state=None, ...),
param_grid={'colsample_bytree': [0.3, 0.7],
'learning_rate': [0.01, 0.05], 'max_depth': [3, 6],
'n_estimators': [3, 5]},
scoring='neg_mean_squared_error', verbose=1)XGBRegressor(base_score=None, booster=None, callbacks=None,
colsample_bylevel=None, colsample_bynode=None,
colsample_bytree=None, early_stopping_rounds=None,
enable_categorical=False, eval_metric=None, feature_types=None,
gamma=None, gpu_id=None, grow_policy=None, importance_type=None,
interaction_constraints=None, learning_rate=None, max_bin=None,
max_cat_threshold=None, max_cat_to_onehot=None,
max_delta_step=None, max_depth=None, max_leaves=None,
min_child_weight=None, missing=nan, monotone_constraints=None,
n_estimators=100, n_jobs=None, num_parallel_tree=None,
predictor=None, random_state=None, ...)XGBRegressor(base_score=None, booster=None, callbacks=None,
colsample_bylevel=None, colsample_bynode=None,
colsample_bytree=None, early_stopping_rounds=None,
enable_categorical=False, eval_metric=None, feature_types=None,
gamma=None, gpu_id=None, grow_policy=None, importance_type=None,
interaction_constraints=None, learning_rate=None, max_bin=None,
max_cat_threshold=None, max_cat_to_onehot=None,
max_delta_step=None, max_depth=None, max_leaves=None,
min_child_weight=None, missing=nan, monotone_constraints=None,
n_estimators=100, n_jobs=None, num_parallel_tree=None,
predictor=None, random_state=None, ...)print("Best parameters:", reg_hyper.best_params_)
print("Lowest RMSE: ", np.sqrt(-reg_hyper.best_score_))
Best parameters: {'colsample_bytree': 0.7, 'learning_rate': 0.05, 'max_depth': 6, 'n_estimators': 5}
Lowest RMSE: 1.577448838744757